接上次闹钟项目更改字符集之后,这几天又需要对线上数据做处理。背景是,同步闹钟的时候会把用户之前删除过的闹钟都同步下来,而删除的闹钟在客户端没有任何显示,也没有任何恢复的操作,对于用户来说其实是完全没有用的数据。当用户的无用历史闹钟增多到一定数量,同步的时候,客户端上报的数据body就特别大,已经超过了Nginx配置的request最大限制,这样就导致了部分老用户无法同步的情况。解决思路其实很简单,将客户端的上报策略修改成分批上传,服务端分批的返回,最后的结果客户端在本地做聚合,显示给用户。但是这需要客户端和服务端共同修改,客户端还要发版审核,现在需要一种比较快速的方式,让用户在尽可能短的时间内可以进行同步。最后决定将数据库中2018年以前用户无用的闹钟进行删除,找到dba同学商量要删除数据,但是很不幸,dba同学告知我们目前他们没有成熟的工具操作,让我们自己写程序删除,他们可以负责备份数据。看来只能靠自己了,接下来就看一下从分析到实现整个删除任务的具体过程。
一、思路分析
需要进行删除的这张表是一个很宽的数据量很大的表,当前共有七千多万条数据,经过筛选查询,发现2018年之前且状态为无效的闹钟数量达到了五千多万,也就是说现在需求是要物理删除这五千多万条数据。需求明确了,下面就要考虑几个问题。
- 要删除的五千多万条数据如何定位?
- 怎样高效地删除这么大量的数据同时保证负载正常?
- 怎样保证集群环境下,删除任务只执行一次?
我们分别看一下解决这些问题的思路。
1.定位目标数据
表中主要字段包括user_id,status,init_time,分别表示闹钟所属的用户id、闹钟状态、闹钟初始化时间。删除的大体思路是通过in user_id字段来delete,那么如何找到要in哪些user_id呢?从上面的分析可以知道,这张表拥有很大的数据量,想要一次delete是不可能的事情,需要进行分批删除,每次in一部分user_id。那么每次的user_id如何获取呢?可以通过分页排序的group by语句得到分批的user_id。
1 | select user_id from clocks order by user_id group by user_id limit 0,500; |
上面的分页查询看上去没什么问题,但是随着翻页次数增大,效率也越来越慢,假设我们翻到了2000页,这个语句查询的2000之前的数据都是无用的,效率特别低下。由数据量分析可知,这张表里通过user_id分组,可以得到200W+数据,如果我们每次分页查询500条,计算可得 最后我们需要将 200W / 500 作为limit的起点,这样的查询是灾难性的。但是通过下面的sql修改,可以大大提高分页的查询效率。
1 | select user_id from clocks where user_id > 0 order by user_id group by user_id limit 500; |
通过where过滤当前页之前的数据,可以大大提高查询效率。只需要每次记下当次分页结果中最大的user_id,下次分页将此user_id作为分页起始条件进行过滤即可。因为我们使用order by进行排序,查询结果都是有序的,可以将每次的user_id结果放进一个LinkedList中,每次使用的时候peekLast()就能得到当前分组的最大user_id。定位目标数据的思路大体就是这样,思路清晰后代码实现也是很容易的。
1 |
|
1 |
|
2.多线程删除
找到了每次分批的user_id条件,接下来就可以进行删除操作了。这么庞大的数据量,每次串行执行delete where,明显效率很低,估计删除完这些数据也要进行几个小时吧。这时我们很容易地想到了使用多个线程同时进行delete操作。因为user_id字段是这张表的索引,所以delete的时候走索引,并不会锁住整个表,所以我们可以使用多个线程同时进行删除。但是由于数据量大,分组要达4000+,我们要使用多少个线程同时工作呢?
这里我们通过 Runtime.getRuntime().availableProcessors() 获取当前可用处理器数量,用来创建线程池。
我们使用 Executors.newFixedThreadPool() 创建固定线程数的线程池,传入的参数就是上面获取的处理器的数量。当工作线程到达了处理器数量,新进来的任务便会进入阻塞队列等待,待工作线程中有任务完成,阻塞队列中的任务再执行。线程池的工作原理,大家应该都已经很熟悉了,在此就不多说了。
多线程执行当然能提高效率,但是我们能将这4000+的任务一下子提交给线程池来执行吗?这样的话cpu会有突然增长,这里我们可以使用限流策略,控制任务进入线程池的速度。Google Guava中提供了一个很好用的限流工具,它就是 RateLimiter,一个基于令牌桶算法实现的限流器,想必大家也都知道。使用RateLimiter可以很方便地实现限流。
通过以上的思考,多线程删除也可以很简单地实现,在文章的后面我会给出实现代码。
3.集群中单点执行任务
应用部署在集群中,但是我们需求的任务只需要一台机器执行即可。我们如何来保证集群中只有一台机器执行这个删除任务呢?
我们可以使用Redis来实现。大体思路如下:
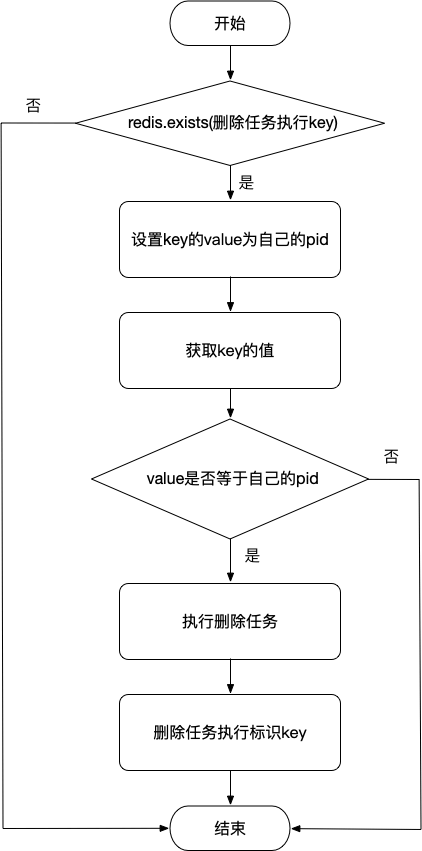
判断标识删除任务执行的Key是否存在,存在的话直接返回,不存在则使用 SETNX 尝试设置Key的value为当前自己的Pid,再次获取key对应的value值,若value和自己当前的pid不同,说明不是当前节点获取的锁,不能执行任务,只有value和当前自己的pid相同时才执行删除任务。这样就可以保证集群中只有一个节点执行了删除任务,在任务执行结束之后要删除key。下面给出流程图,思路一目了然。
4.在哪里触发任务
分析了如何定位以及删除数据,那我们如何触发任务的执行呢?这里我在配置文件中设置了一个开关,用来标识本次启动是否需要执行删除任务。这个开关和上面提到的redis key共同决定是否在当前节点执行任务。
什么时机进行删除呢?因为删除任务中使用了spring bean service,所以应该在spring容器初始化bean完成后执行删除任务。
可以通过实现 ApplicationRunner 接口,实现接口的run方法来执行我们的任务。查阅springboot官方文档

二、代码实现
通过以上分析,实现思路已经非常清晰,下面给出实现代码,仅供参考。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
234j
public class DeleteClockTask implements Runnable {
private String name;
private List<Long> userIds;
private ClockDeleteService clockDeleteService;
public DeleteClockTask(String name, List<Long> userIds) {
this.name = name;
this.userIds = userIds;
this.clockDeleteService = (ClockDeleteService) SpringContextUtils.getBeanByClass(ClockDeleteService.class);
}
public void run() {
log.info("delete clock task {} start...", name);
clockDeleteService.deleteUnusedClock(userIds);
log.info("delete unused clock task {} end.", name);
}
}
1 |
|
三、线上执行
经过测试环境反复测试,最终挑了个风和日丽的日子,准备在生产环境执行。
合并master,开始部署,盯着日志,静静等待…
线上删除任务共分为了4014个组,按每秒钟2组的速度进入线程池,开始执行删除任务,观察cpu使用率,基本稳定,没有出现激增。半个多小时后,所有任务执行完成。一共删除了58115102条数据,至此这次删除历史数据的任务完成。
第一次在线上物理删除这么大量的数据,仅此记录一下本次处理的思路和实现方法。